|
|
Disclaimer
The material in this manual is for informational purposes only. The products it describes are subject to change without prior notice, due to the manufacturer’s continuous development program. Rampiva Inc. makes no representations or warranties with respect to this manual or with respect to the products described herein. Rampiva Inc. shall not be liable for any damages, losses, costs or expenses, direct, indirect or incidental, consequential or special, arising out of, or related to the use of this material or the products described herein.
The Relativity-related modules may only be used by parties with valid licenses for Relativity®, a product of Relativity ODA LLC. Relativity ODA LLC does not test, evaluate, endorse or certify this product.
© Rampiva Inc. 2020 All Rights Reserved
Quick Start
Designing a workflow
Workflows can be created and edited in the Workflow Designer module. To run this module, start Nuix Workbench and open the Scripts → Rampiva → Workflow Designer menu.
Executing a workflow
After designing a workflow, it can be executed using the Workflow Execution module. This module can be run either in the currently open Nuix Workbench case, or in a new or existing case which is not open. To run this module, use the Scripts → Rampiva → Workflow Execution menu.
Quick run
To run a single operation without creating a workflow, use Quick Run modules. To run a Quick Run module, first open a case in Nuix Workbench and the use the Scripts → Rampiva → Quick Run menu to select the operation that needs to be executed.
1. Licensing
When starting either the Workflow Designer or Workflow Execution module, the module will look for and validate the license on your system. If licence file is required, please contact support@rampiva.com
The default location of the licence file can be specified using the registry key HKEY_LOCAL_MACHINE\SOFTWARE\Rampiva\Workflow for Nuix\LicenceFile
|
2. Workflow Design
2.1. Concepts
A workflow is comprised of a series of operations which execute in sequence. When running the Workflow Designer module, you are presented with a blank workflow. Operations can be added to the workflow using menu Edit → Add Operation.
The order of operations in the workflow can be changed using the Edit menu and the Move to Top, Move Up, Move Down and Move To Bottom options.
When designing a workflow, parameters can be used in the workflow along with static text in every field which accepts user input such as search queries, file paths, production sets names, etc. See Parameters for more details.
General options can be set using the Edit → Options menu. These options are stored in the user profile and determine whether the system checks for updates whenever Rampiva Workflow is started and whether telemetry is enabled.
After completing the design of a Workflow, the workflow can be saved using the File → Save Workflow menu. At this point, the Workflow Designer window can be closed or can be switch to the Workflow Execution module using File → Workflow Execution.
| It’s possible to disable the execution of certain operations in the workflow without deleting them from the workflow, by using the Edit → Enable / Disable / Toggle Enabled in the Workflow Designer. |
2.2. Operations
2.2.1. Configuration
Profiles
This operation allows for using the settings from a Nuix Configuration profile and/or a Nuix Processing profile. The use of Processing profiles is recommended over Configuration profiles.
By default, Nuix stores configuration profiles in the user-specific folder %appdata%\Nuix\Profiles. To make a configuration profile available to all users, copy the corresponding .npf file to %programdata%\Nuix\Profiles.
|
| Only a subset of settings from the Configuration profiles are supported in Rampiva Workflow, including Evidence Processing Settings (Date Processing, MIME Type, Parallel Processing), Legal Export (Export Type - partial, Load File - partial, Parallel Processing). |
Custom parameters
Custom parameters, which will exist during the scope of the execution of the workflow can be manually defined or loaded from a TSV file, along with a value, description and validation regex.
| When using the Sticky parameters option, parameters values will be stored in the user profile during execution and will be available in subsequent workflow executions under the same profile, provided that these values are not overwritten. |
Password settings
Passwords are used during the loading and re-loading of the data in Nuix. This section allows for specifying the use of a password list of passwords file.
Parallel processing settings
The worker settings can either be extracted from the Nuix settings (see above) or can be explicitly provided in the workflow.
For local workers, these settings can be used to specify the number of local workers, the memory per worker and the worker temporary directory.
| Nuix does not support running the OCR Operation and Legal Export operation with no local workers. If a value of 0 is specified in the local workers for these operations, Rampiva Workflow will start the operation with 1 local worker and as many remote workers as requested. |
For remote workers, the number of remote workers, the worker broker IP address and port must be specified.
| The worker broker must be running before starting the workflow, to avoid an unrecoverable error from Nuix that will halt the execution of the worker. |
| If the number of remote workers requested is not available immediately when starting the operation that requires workers, Rampiva Workflow will keep trying to assign the required number of workers up until the end of the operation. |
Parallel processing settings can also be set using the following parameters:
-
{local_worker_count}- The number of local workers to run; -
{local_worker_memory}- The memory (in MB) of each local worker; -
{broker_worker_count}- The number of remote workers to assign;
Prompt
When checked, the Prompt for configuration settings at execution displays a pop-up with the parameters and the password settings.
| When using workflow in Rampiva Scheduler, select the Prompt for configuration settings at execution option to have the parameters presented to the user when queuing the workflow. |
2.2.2. Use Case
This operation opens an existing Nuix case or creates one, depending on the Method option specified.
The case timezone can be overwritten by setting parameter {case_timezone_id}. See Joda Time Zones for a list of valid timezone IDs.
2.2.3. Add to Compound Case
This operation adds existing cases to the currently opened Nuix case.
| The current Nuix case must be a compound case, otherwise this operation will fail during execution. |
2.2.4. Add Evidence
This operation adds evidence to the case and it can be executed in one of two difference modes: Prompt at execution which will show a pop-up when the workflow execution reaches this operation, requiring the using to specify what evidence to add to the case, and Predefined which allows for all details to be specified in the workflow.
If the option to Create separate evidence container for each file and subfolder in the source path is checked, an evidence container will be created for each subfolder and the contents of the evidence container will correspond to the contents of the folder. An evidence container will also be created for each file directly under the source path, with only the contents of the evidence container being the file in question.
The source data timezone can be overwritten by setting parameter {data_timezone_id}. See Joda Time Zones for a list of valid timezone IDs.
| The Predefined mode allows for a wider range of options than the Prompt at execution mode. |
Source Data
The details of the source data to be added to the case are specified using the Content, Evidence name and Source time zone fields.
Deduplication
If this option is selected, data will be deduplicated at ingestion. Unless data will be added to the case in a single batch, the option Track and deduplicate against multiple batchloads needs to be selected.
Handling of duplicate items:
-
Metadata-only processing: Deduplication status is tracked using the metadata field
Load original. Top-level original items will have the valuetruein this field and will have all typical metadata and descendants processed - the descendants will not have this metadata field populated. Top-level duplicate items will have valuefalsein this field and no other properties except for the metadata fieldLoad duplicate of GUIDwhich will indicate the GUID of the original document with the same deduplication key as the duplicate document.
To query all items that were not flagged as duplicates, use query !boolean-properties:"Load original":false.
|
-
Skip processing entirely will completely skip items identified as duplicates and no reference of these items will exist in the case.
Deduplication method:
-
Top-level MD5: Uses the MD5 hash of the top-level item.
-
Email Message-ID: Uses the email Message-ID property from the first non-blank field: Message-ID, Message-Id, Mapi-Smtp-Message-Id, X-Message-ID, X-Mapi-Smtp-Message-Id, Mapi-X-Message-Id, Mapi-X-Smtp-Message-Id.
-
Email MAPI Search Key: Uses the email MAPI Search Key property from the first non-blank field: Mapi-Search-Key, X-Mapi-Search-Key.
| For a deduplication result similar to the post-ingestion Nuix ItemSet deduplication, check option Top-level MD5 only. For the most comprehensive deduplication result, check all three options. |
| Emails in the Recoverable Items folder are not considered for deduplication based on Message-ID and MAPI Search Key, due to the fact that data in this folder is typically unreliable. |
Date filter
All modes other than No filter specify the period for which data will be loaded. All items that fall outside of the date filter will be skipped entirely and no reference of these items will exist in the case.
Mime type filter
Allows to set a filter to restrict data of certain mime-types to specific names.
For example, the filter mode Matches, with mime-type application/vnd.ms-outlook-folder and item name Mailbox - John Smith will have the following effect:
-
Items which are in a PST or EDB file, must have the first Outlook Folder in their path named Mailbox - John Smith.
-
Items which are not in a PST or EDB file are not affected.
| The Mime type filter can be used to select specific folders for loading from an Exchange Database (EDB) file. |
Add Evidence from Evidence listing
When selecting the Scope option Evidence listing, the Source path is expected to point to a tab-separated file (TSV) with the following columns:
-
Name: The name of the evidence container
-
Path: The path to the file or folder to load
-
Custodian: Optional, the custodian value to assign
-
Timezone: Optional, the timezone ID to load the data under. See Joda Time Zones for a list of valid timezone IDs.
-
Encoding: Optional, the encoding to load the data under.
If additional columns are specified, these will be set as custom evidence metadata.
If optional settings are not provided, the default settings from the Add Evidence operation will be used.
Sample evidence listing:
Name Path Custodian Encoding Timezone Sample Custom Field Another Sample Field
Evidence1 C:\Data\Folder1 Morrison, Jane UTF-8 Europe/London Value A Value B
Evidence2 C:\Data\Folder2 Schmitt, Paul Windows-1252 Europe/Berlin Value C Value D2.2.5. Add Evidence Repository
This operation adds an evidence repository to the case. The typical Nuix options can be used to customize the evidence repository settings.
| This operation does not load data into the case. The Rescan Evidence Repositories operation must be used to add data. |
2.2.6. Rescan Evidence Repositories
This operation rescans all evidence repositories and adds new data to the case.
The option No new evidence behavior can be used to show a warning, trigger an error, or finish the execution of the workflow if no new evidence is discovered.
2.2.7. Detect and Assign Custodians
This operation detects custodian names using one of the following options:
-
Set custodians from folder names sets the custodian to the same name as the folder at the specified path depth.
-
Set custodians from folder names with typical custodian names attempts to extract custodian names from the folder names, where the folder names contain popular first names, up to the specified maximum path depth.
-
Set custodians from PST files sent emails sender name attempts to extract custodian names from the name of the sender of emails in the Sent folder.
-
Manual interactive assignment prompts the user with a window which will indicate the custodian names detected (if any) and which allows the user to make any changes such as assigning new custodians, changing proposed assignments or skipping the assignment of custodians altogether.

In the Assign Custodians prompt window, the style with which the Custodian name is printed has the following meanings:
-
Grey italic: the custodian value was previously assigned, and no value is assigned during this run.
-
Black italic: the custodian value was previously assigned, and the same value is assigned during this run.
-
Black: a custodian value different that what was previously assigned is assigned during this run.
The Assign Custodians prompt offers the following options:
-
Accept: accept the custodian assignments shown in black and apply them to the data.
-
Reset: reset any changes performed by the user in the prompt window.
-
Cancel: skip assigning custodians and continue with the remaining workflow operations.
The settings of this operation can also be controlled using the following parameters:
-
{set_custodian_from_folder_name}- Enable or disable the Set custodians from folder names option; -
{custodian_folder_level}- The folder depth corresponding to the Set custodians from folder names option; -
{set_custodian_from_typical_folder_name}- Enable or disable the Set custodians from folder names with typical custodian names option; -
{max_custodian_typical_folder_level}- The max folder depth corresponding to the Set custodians from folder names with typical custodian names option. -
{set_custodian_from_pst}- Enable or disable the Set custodians from PST files sent emails sender name option;
The parameters for enabling or disabling options can be set to true, yes, or Y to enable the option, and to anything else to disable the option.
|
2.2.8. Exclude Items
This operation excludes items from the case that match specific search criteria.
Entries can be added to the exclusions list using the + and - buttons, or loaded from exclusions list from a tab-separated values (TSV) file.
The exclusions can also be loaded from a file during the workflow execution, using the Exclusions file option.
| Parameters can be used in the Exclusions file path, to select an exclusion file dynamically based on the requirements of the workflow. |
2.2.9. Include Items
This operation includes items previously excluded.
Excluded items which are outside of the scope query will not be included.
Items belonging to all exclusion categories can be included, or alternatively, exclusion names can be specified using the + and - buttons, or loaded from a single-column TSV file.
2.2.10. Add to Item Set
This operation adds items to an existing Item Set or creates a new Item Set if one with the specified name does not exist.
In addition to the standard Nuix deduplication options, Rampiva Workflow offers two additional deduplication methods:
-
Message ID: Uses the email Message-ID property from the first non-blank field: Message-ID, Message-Id, Mapi-Smtp-Message-Id, X-Message-ID, X-Mapi-Smtp-Message-Id, Mapi-X-Message-Id, Mapi-X-Smtp-Message-Id.
-
Mapi Search Key: Uses the email MAPI Search Key property from the first non-blank field: Mapi-Search-Key, X-Mapi-Search-Key.
When performing a deduplication by family based on Message-ID or MAPI Search Key, two batches will be created: one for top-level items (with suffix TL) and another one for non-top-level items (with suffix NonTL). To query for original items in both of these batches, use syntax:item-set-batch:("{last_item_set_originals_batch} TL" OR "{last_item_set_originals_batch} NonTL")
|
2.2.11. Remove from Item Set
This operation removes items, if present, from the specified Item Set.
2.2.12. Delete Item Set
This operation deletes the specified Item Set.
2.2.13. Add Items to Digest List
This operation adds items to a digest list with the option to create the digest list if it doesn’t exist.
A digest list can be created in one of the three digest list locations:
-
Case: Case location, equivalent to the following subfolder from the case folder
Stores\User Data\Digest Lists -
User: User profile location, equivalent to
%appdata%\Nuix\Digest Lists -
Local Computer: Computer profile location, equivalent to
%programdata%\Nuix\Digest Lists
2.2.14. Remove Items from Digest List
This operation removes items, if present, from the specified digest list.
2.2.15. Manage Digest Lists
This operation performs an operation on the two specified digest lists and then saves the resulting digest list in the specified digest list location.
List of operations:
-
Add: Produces hashes which are present in either digest list A or digest list B;
-
Subtract: Produces hashes present in digest list A but not in digest list B;
-
Intersect: Produces hashes which are present in both digest list A and digest list B.
2.2.16. Delete Digest List
This operation deletes the specified digest list, if it exists, from any of the specified digest list locations.
2.2.17. Digest List Import
This operation imports a text or Nuix hash file into the specified digest list location.
Accepted file formats:
-
Text file
(.txt, .csv, .tsv). If the file contains a single column, hashes are expected to be provided one per line. If the file contains multiple columns, a column with the header nameMD5is expected -
Nuix hash
(.hash)file
2.2.18. Digest List Export
This operation exports a Nuix digest list to the specified location as a text file. The resulting text file contains one column with no header and one MD5 hash per line.
2.2.19. Search and Tag
This operation tags items from the case that match specific search criteria.
Options
If the Identify families option is selected, the operation will search for Family items and Top-Level items of items with hits for each keyword. If the Identify exclusive hits ("Unique" hits) option is selected, the operation will search for Exclusive hits (items which only hit on one keyword), Exclusive family items (items for which the entire family only hit on one keyword) and Exclusive top-level items (also items for which the entire family only hit on one keyword). If the Compute size option is selected, the operation will compute the audited size for Hits and Family items. If the Compute totals option is selected, the operation will compute the total counts and size for all keywords.
Tags
If the Assign tags option is selected, items will be tagged under the following tag structure:
-
Tag name-
Hits
-
Tag name: Items that matched the search query.
-
-
Families
-
Tag name: Families of items that matched the search query.
-
-
TopLevel
-
Tag name: Top-level items of items that matched the search query.
-
-
ExclusiveHits
-
Tag name: Items that hit exclusively on the keyword.
-
-
ExclusiveFamilies
-
Tag name: Families that hit exclusively on the keyword.
-
-
ExclusiveTopLevel
-
Tag name: Top-level items of families that hit exclusively on the keyword.
-
-
If the Remove previous tags with this prefix option is selected, all previous tags starting with the Tag prefix will be removed, regardless of the search scope, according to the Remove previous tags method.
| This operation can be used with an empty list of keywords and with the Remove previous tags with this prefix enabled, in order to remove remove tags that have been previously applied either by this operation or in another way. |
The Remove previous tags with this prefix method renames Tag prefix to Rampiva|SearchAndTagOld|Tag prefix_{datetime}. Although this method is the fasted, after running the Search and Tag
operation multiple times it can create a large number of tags which might slow down manual activities in Nuix Workbench.
Reporting
This option generates a search report in an Excel format, based on a template file.
If a custom template is not specified, the operation will use the default Rampiva template. To create a custom template, first run the Processing Report operation with default settings. Then, make a copy of the latest template file from %programdata%\Rampiva\Workflow For Nuix\Templates. When finished, modify the workflow to point to the newly created custom template file.
|
Keywords
The keywords can either be specified manually in the workflow editor interface, or loaded from a tab-separated values (TSV) file, with the fist column containing the keyword name or tag and the second column containing the keyword query.
Alternatively, the path to a keywords file can be supplied which will be loaded when the workflow executes.
2.2.20. Search and Assign Custodians
This operation assigns custodians to items from the case that match specific search criteria.
Entries can be added to the custodian/query list using the + and - buttons, or loaded from a tab-separated values (TSV) file.
2.2.21. Tag Items
This operation searches for items in the scope query.
Then it matches the items to process either as the items in scope, or duplicates of the items in scope, as individuals or by family.
The tag name is applied to either the items matched (Matches), their families (All families), their descendants (All Descendants), items matched and their descendants (Matches and Descendants) or their families top-level items (Top-level).
2.2.22. Untag Items
This operation removes tags for the items in the scope query.
Optionally, if the tags are empty after the items in scope are untagged, the remove method can be set to delete the tags.
When the option to remove tags starting with a prefix is specified, tags with the name of the prefix and their subtags are removed. For example, if the prefix is set to Report, tags Report and Report|DataA will be removed but not Reports.
2.2.23. Match Items
This operation reads a list of MD5 and/or GUID values from the specified text file. Items in scope with a matching MD5 and/or GUID values of the items in scope are tagged with the value supplied in the Tag field.
2.2.24. Date Range Filter
This operation filters items in the scope query to items within the specified date range using either the item date, top-level item date or a list of date-properties.
Then it applies a tag or exclusion similar to Tag Items.
Use \* as a date property to specify all date properties.
|
2.2.25. Find Items with Words
This operation analyzes the text of the items in scope and determines if the item is responsive if the number of words respects the minimum and maximum count criteria.
The words are extracted by running by splitting the text of each item using the supplied regex.
Sample regex to extract words containing only letters and numbers:
[^a-zA-Z0-9]+Sample regex to extract words containing any character, separated by a whitespace character (i.e. a space, a tab, a line break, or a form feed)
\s+2.2.26. Filter Emails
This operation performs advanced searches for emails, based on recipient names, email addresses and domain names.
The Wizard feature prepopulates the filtering logic based on one of the following scenarios:
-
Tag internal-only emails
-
Tag communications between two individuals only
-
Tag communications within a group
2.2.27. Detect Attachment-Implied Emails
This operation must be used in conjunction with the Cluster Run operation from Nuix. First, generate a Cluster Run using Nuix Workstation and then run the Detect Attachment-Implied Emails operation to complement the identification of inclussive and non-inclussive emails.
If no cluster run name is specified, the operation will process all existing cluster runs.
Items will be tagged according to the following tag structure:
-
Threading
-
Cluster run name
-
Items
-
Inclusive
-
Attachment-Inferred
-
Singular
-
Ignored
-
Endpoint
-
-
Non Inclusive
-
-
All Families
-
Inclusive
-
Attachment-Inferred
-
Singular
-
Ignored
-
Endpoint
-
-
Non Inclusive
-
-
-
To select all data except for the non-inclusive emails, use querytag:"Threading|Cluster run name|All Families|Inclusive|*"
|
| This operation should be used on cluster runs that contain top-level emails only, clustered using email threads. Otherwise, the operation will produce inconsistent results. |
2.2.28. Reload Items
This operation reloads from source the items matching the scope query.
| This operation can be used to decrypt password protected files when preceded by a Configuration operation which defines passwords and if the Delete encrypted inaccessible option is used. |
2.2.29. Replace Items
This operation replaces case items with files which are named with the MD5 or GUID values of the source items.
2.2.30. Delete Items
This operation deletes items in the scope query and their descendants.
| This is irreversible. Deleted items are removed from the case and will no longer appear in searches. All associated annotations will also be removed. |
2.2.31. Replace Text
This operation replaces the text stored for items matching the scope query, if an alternative text is provided in a file which is named based on the items MD5 or GUID values.
| This operation can be used after an interrupted Nuix OCR operation, to apply the partial results of the OCR operation, by copying all of the text files from the OCR cache to a specific folder and pointing the Replace Text operation at that folder. |
| This operation searches for files at the root of the specified folder only and ignores files from subfolders. |
2.2.32. Remove Text
This operation removes the text stored for items matching the scope query.
| This operation can be used to remove text from items for which Nuix stripped the text during loading but where no meaningful text was extracted. |
2.2.33. Redact Text
This operation runs regex searches agains the text of the items in scope, and redacts all matches.
The Redaction definition file can be a text file with a list of regular expressions, or a tab-separated file columns Name and Regex.
2.2.34. OCR
This operation performs OCR on the items identified by the scope query, using standard Nuix options.
2.2.35. Generate Duplicate Custodians Field
This operation will generate a CSV file with the list of duplicate custodians in the case. See Generate Duplicate Fields for a description of the available options.
| Running without the DocIDs selected in the Original fields will significantly improve execution time. |
| This operation is less memory-intensive than the Generate Duplicate Fields operation. |
2.2.36. Generate Domain Fields
This operation will extract email domains from items in the Scope.
The resulting extracted domain fields can be saved to a CSV file and/or can be assigned as custom metadata to the items in Scope.
2.2.37. Generate Duplicate Fields
This operation will identify all items that match the Update items scope query and that have duplicates in the larger Search scope query.
The duplicate items are identified based on the following levels of duplication:
-
As individuals: Items that are duplicates at the item level.
-
By family: Items that are duplicates at the family level.
-
By top-level item: Only the top-level items of items in scope that are duplicates are identified.
| When using the deduplication option By top-level item, ensure that you are providing complete families in the search and update scope.. |
When an item in the Update item scope with duplicates is identified, this operation will generate duplicate fields capturing the properties of the duplicate items. The following duplicate fields are supported:
-
Custodians
-
Item Names
-
Item Dates
-
Paths
-
Tags
-
Sub Tags
-
GUIDs
-
Parent GUIDs
-
Top-Level Parent GUIDs
-
DocIDs
-
Lowest Family DocID
The Results inclusiveness option determines whether the value from the current original item should be added to the duplicate fields. For example, if the original document has custodian Smith and there are two duplicate items with custodians Jones and Taylor, the Alternate Custodians field will contain values Jones; Taylor whereas the All Custodians field will contain values Jones; Taylor; Smith.
The resulting duplicate fields can be saved to a CSV file and/or can be assigned as custom metadata to the items in the Update items scope.
For help with date formats, see Joda Pattern-based Formatting for a guide to pattern-based date formatting.
2.2.38. Generate Printed Images
This operation generate images for the items in scope using the specified Imaging profile.
2.2.39. Populate Binary Store
This operation populates the binary store with the binaries of the items in scope.
2.2.40. Assign Custom Metadata
This operation adds custom metadata to the items in scope. A tab-separated values (TSV) input file with no quotes is required.
The file header starts with either GUID or DocID, followed by the names of the metadata fields to be assigned.
Each subsequent line corresponds to an item that needs to be updated, with the fist column containing the GUID or DocID of the item and the
the remaining columns containing the custom metadata.
Example:
DocID HasSpecialTerms NumberOfSpecialTerms DOC00001 Yes 5 DOC00002 Yes 1 DOC00003 No 0 DOC00004 Yes 7
2.2.41. Add Items to Production Set
This operation adds items matching the scope query to a production set.
When adding items to a production set, the following sort orders can be applied:
-
No sorting: Items are not sorted.
-
Top-level item date (ascending): Items are sorted according to the date of the top-level item in each family, in ascending order.
-
Top-level item date (descending): Items are sorted according to the date of the top-level item in each family, in descending order.
-
Evidence order (ascending): Items are sorted in the same way in which they appear in the evidence tree, in ascending order.
The item numbering can be performed either at the Document ID level, or at the Family Document ID level. In the latter case, the top-level item in each family will be assigned a Document ID according to the defined prefix and numbering digits. All descendants from the family will be assigned a Document ID which is the same as the one of the top-level item, and a suffix indicating the position of the descendant in the family.
The document ID start number, the number of digits and the number of family digits can be specified using custom parameters:
-
{docid_start_numbering_at}- Select the option Start numbering at in the configuration of the Add Items to Production Set operation for this parameter to have an effect; -
{docid_digits} -
{docid_family_digits}- Select the numbering scheme Family Document ID in the configuration of the Add Items to Production Set operation for this parameter to have an effect;
2.2.42. Set Relativity Workspace and Folder
This operation connects to the Relativity environment and retrieves the artifact IDs of the Workspace and Folder path specified:
-
Host name- The Relativity host name, for example relativity.example.com. -
Service endpoint- The Relativity Service Endpoint, for example/relativitywebapi. -
Endpoint type- The Relativity Endpoint Type, for exampleHTTPS. -
User name- The user name used to perform the import into Relativity. -
Password
The value entered in this field will be stored in clear text in the workflow file - a password SHOULD NOT be entered in this field. Instead, set this
field to a protected parameter name, for example {relativity_password} and see section Protected Parameters for instructions on how to set protected parameter values.
|
-
Workspace identifier- The Name or Artifact ID of the Relativity workspace which was created prior to running this operation. -
Folder path- The path inside the workspace. If blank, this will retrieve the folder corresponding to the root of the workspace. -
Create folder path if it does not exist:- If checked, the specified folder path will be created in the workspace if it does not exist. -
Import threads- The number of parallel threads to use for Relativity uploads, such as Legal Export, Relativity Loadfile Upload, Relativity Metadata Overlay, Relativity CSV Overlay. -
Metadata threads- The number of parallel threads to use for Relativity metadata operations, such as Create Relativity Folders.
The Import threads value is independent of the number of Nuix workers. When using more than 1 import thread, the loadfile or the overlay file
will be split and data will be uploaded to Relativity in parallel. Because multiple threads load the data in parallel, this method will impact the order in which documents
appear in Relativity when no sort order is specified.
|
-
Client version- When unchecked, Rampiva will use the Relativity client version which is the closest match to the Relativity server version. When checked, Rampiva will use the specified Relativity client version, if available.
2.2.43. List Relativity Documents
This operation lists all documents present in the Relativity Workspace.
The following settings are available:
-
Scope query- Cross references the DocIDs from the Relativity workspaces against the documents in the Nuix case in this scope. -
Tag matched items as- The tag to assign to documents in scope in the Nuix case which have the same DocIDs as documents from the Relativity workspace. -
Export DocIDs under- The path and name of the file to which to write the list of DocIDs from the Relativity workspaces. Each line will contain a single DocID.
2.2.44. Create Relativity Folders
This operation creates folders in the Relativity Workspace from the listing CSV file. The listing file must have a single column and the name of the column must contain the word Folder or Path or Location.
| When uploading documents to Relativity with a complex folder structure, it is recommended to use the Create Relativity Folders before the upload to prepare the folder structure. |
2.2.45. Relativity Loadfile Upload
This operation loads a Concordance loadfile to Relativity.
The following settings are required:
-
Fields mapping file- Path to JSON file mapping the Nuix Metadata profile to the Relativity workspace fields. To generate a mapping file, first run a Legal Export to Relativity manually using Nuix Workstation and get a copy of themapping.jsonfile create in the export folder. If blank, fields in the loadfile will be mapped to fields with the same names in the Relativity workspace. -
Detect export in parts- Detects the existence of loadfiles in subfolders in the specified location, and uploads all detected loadfiles sequentially.
This operation sets the Relativity OverwriteMode property to Append when loading the documents into Relativity.
|
| The Legal Export operation can be used to export the loadfile and upload to Relativity, with the added benefit of uploading export parts as soon as they become available. |
2.2.46. Relativity Metadata Overlay
This operation exports metadata from the Nuix items in the scope query and overlays it to Relativity.
This operation requires the prior use of the Use Relativity Workspace operation. The following settings are required:
-
Fields mapping file- Path to JSON file mapping the Nuix Metadata profile to the Relativity workspace fields. To generate a mapping file, first run a Legal Export to Relativity manually using Nuix Workstation and get a copy of themapping.jsonfile create in the export folder. If blank, fields in the loadfile will be mapped to fields with the same names in the Relativity workspace.
This operation sets the Relativity OverwriteMode property to Overlay when loading the metadata into Relativity.
|
2.2.47. Relativity CSV Overlay
This operation overlays the metadata from the specified overlay file to Relativity.
This operation requires the prior use of the Use Relativity Workspace operation. The following settings are required:
-
Fields mapping file- Path to JSON file mapping the Nuix Metadata profile to the Relativity workspace fields. To generate a mapping file, first run a Legal Export to Relativity manually using Nuix Workstation and get a copy of themapping.jsonfile create in the export folder. If blank, fields in the loadfile will be mapped to fields with the same names in the Relativity workspace.
2.2.48. Legal Export
This operation performs a legal export, using standard Nuix options.
| Use the Imaging profile and Production profile options to control the parameters of images exported during a legal export. |
The Split export at option will split the entire export (including loadfile and export components) into multiple parts of the maximum size specified, and will include family items.
Export to Relativity
When selecting the Export type Relativity, the loadfile will be uploaded to Relativity during the legal export operation. If the export is split into multiple parts, each part will be uploaded as soon as it is available and previous parts finished uploading.
This option requires the prior use of the Use Relativity Workspace operation. The following settings are required:
-
Fields mapping file- Path to JSON file mapping the Nuix Metadata profile to the Relativity workspace fields. To generate a mapping file, first run a Legal Export to Relativity manually using Nuix Workstation and get a copy of themapping.jsonfile create in the export folder. If blank, fields in the loadfile will be mapped to fields with the same names in the Relativity workspace.
2.2.49. Case Subset Export
This operation will export the items in scope in a case subset under the specified parameters.
2.2.50. Logical Image Export
This operation will export the items in scope in a Nuix Logical Image (NLI) container.
2.2.51. Metadata Export
This operation will export the metadata of items matching the scope query, using the selected metadata profile.
The following sort orders can be applied:
-
No sorting: Items are not sorted.
-
Top-level item date (ascending): Items are sorted according to the date of the top-level item in each family, in ascending order.
-
Top-level item date (descending): Items are sorted according to the date of the top-level item in each family, in descending order.
-
Evidence order (ascending): Items are sorted in the same way in which they appear in the evidence tree, in ascending order.
| The Max Path Depth option does not offer any performance advantages - all items matching the scope query are processed and items exceeding the max path depth are not outputted to the resulting file. |
2.2.52. Word-List Export
This operation will export a list of words from the items matching the scope query.
The words are extracted by running by splitting the text of each item using the supplied regex.
Sample regex to extract words containing only letters and numbers:
[^a-zA-Z0-9]+Sample regex to extract words containing any character, separated by a whitespace character (i.e. a space, a tab, a line break, or a form feed)
\s+Words which are shorter than the min or longer than the max length supplied are ignored.
2.2.53. Notify
This operation shows an interactive notification window and/or sends an email, with a customized message.
If the Interactive Notification option is selected, the workflow execution will be paused until the user dismisses the notification.
| The Interactive Notification option can be used to perform quality control on the workflow execution and stop execution if the required criteria is not met. |
If the Email Notification option is selected, an email will be sent to the specified email address. The default options in this section send an email using the public Google servers. To obtain information about the SMTP email server and port used in your environment, contact your network administrator.
The value entered Password field will be stored in clear text in the workflow file - a password SHOULD NOT be entered in this field. Instead, set this
field to a protected parameter name, for example {smtp_password} and see section Protected Parameters for instructions on how to set protected parameter values.
|
2.2.54. Processing Report
This operation generates a processing report in an Excel format, based on a template file.
If a custom template is not specified, the operation will use the default Rampiva template. To create a custom template, first run the Processing Report operation with default settings. Then, make a copy of the latest template file from %programdata%\Rampiva\Workflow For Nuix\Templates. When finished, modify the workflow to point to the newly created custom template file.
|
The default options from this operation generate a report with a predefined number of stages:
-
Source data
-
Extracted
-
Material
-
Post exclusions
-
Post deduplication
-
Export
The default options also include several predefined views, with each view corresponding to a sheet in the Excel report:
-
Processing overview
-
Material items by custodian
-
Export items by custodian
-
Material items by year
-
Export items by year
-
Material items by type
-
Export items by type
-
Material items by extension
-
Export items by extension
-
Material images by dimensions
-
Export images by dimensions
-
Irregular items
-
Exclusions by type
By default, sizes are reported in Gibibytes ("GiB"). 1 GiB = 1024 x 1024 x 1024 bytes = 1,073,741,824 bytes. The size unit can be changed in the view options pane.
|
Each stage and view can be customized, removed and new stages and views can be added.
Generate Processing Report from multiple cases
The Additional cases option can be used to generate a single report from multiple cases, by specifying the location of the additional cases that need to be considered. Items are evaluated from the main workflow case first, and then from the additional cases, in the order provided. If an item exists in multiple cases with the same GUID, only the first instance of the item is reported on.
| When using the Additional cases option to report on a case subset as well as the original case, run the report from the case subset and add the original case in the Additional cases list. This will have the effect of reporting on the case subset items first, and ignoring the identical copies of these items from the original case. |
2.2.55. Tree Size Count Report
This operation will generate a tree report including the size and count of items in the scope.
If the first elements from the path of items should not be included in the report, such as the Evidence Container name and Logical Evidence File name, increase the value of the Omit path prefixes option.
The Max path depth option limits the number of nested items for which the report will be generated.
| See Processing Report for information on using a custom template and size units. |
2.2.56. Run External Application
This operation will run an executable file with specified arguments and wait for it to finish.
2.2.57. Script
This operation will run either the Script code supplied or the code from a Script file in the context of the Nuix case.
| This operation can be used to integrate existing in-house scripts in a workflow. |
Static parameters
All case parameters are evaluated before the script is started, and can be accessed as attributes in the script execution context without the curly brackets. For example, to print the contents of the case folder, following python script can be used:
import os
print "Contents of case folder: "+case_folder
for f in os.listdir(case_folder):
print fDynamic parameters
To retrieve dynamic parameter values and to set parameter values, use the methods put(String name, String value) and get(String name) of the parameters helper object, for example:
print "Setting parameter {param1}"
parameterName = parameters.put("{param1}","Test Value from Script1")
print "Parameter "+parameterName+" has value "+parameters.get(parameterName)
print ""
print "Setting parameter {PAraM2}"
parameterName = parameters.put("{PAraM2}","Test Value from Script2")
print "Parameter "+parameterName+" has value "+parameters.get(parameterName)When setting parameters, the specified parameter name is normalized and returned in the method call.
| See section Parameters for a list of built-in parameters. |
| For assistance with creating custom scripts or for integrating existing scripts into Rampiva Workflow, please contact us at info@rampiva.com. |
Workflow execution
The workflow execution can be manipulated live from the Script operation using the following methods from the workflowExecution helper object:
-
stop()- Stops the workflow execution -
pause()- Pauses the workflow execution -
appendWorkflow(String pathToWorkflowFile)- Appends the operations from workflow from filepathToWorkflowFileto the end of the current workflow. -
appendWorkflowXml(String workflowXml)- Appends the operations from workflow XMLworkflowXmlto the end of the current workflow. -
insertWorkflow(String pathToWorkflowFile)- Inserts the operations from workflow from filepathToWorkflowFileafter the current Script operation. -
insertWorkflow(String workflowXml)- Inserts the operations from workflow XMLworkflowXmlafter the current Script operation. -
goToOperation(int id)- Jumps to operation with specified id after the Script operation completes. To jump to the first operation, specify an id value of 1. -
goToNthOperationOfType(int n, String type)- Jumps to nth operation of the specified type fronm the workflow after the Script operation completes. -
goToOperationWithNoteExact(String text)- Jumps to the first operation in the workflow for which the note equals the specified text. -
goToOperationWithNoteContaining(String text)- Jumps to the first operation in the workflow for which the note contains the specified text. -
goToOperationWithNoteStartingWith(String text)- Jumps to the first operation in the workflow for which the note contains the specified text. -
getCurrentOperationId()- Returns the id of the current Script operation. -
getOperationsCount()- Returns the id of the last operation in the workflow. -
clearStickyParameters()- Remove all sticky parameters set in the user profile.
Example of script that restarts execution twice and then jump to the last operation in the workflow:
countString = parameters.get("{execution_count}")
if ("{execution_count}" in countString):
countString="0"
count=int(countString)
count=count+1
parameters.put("{execution_count}",str(count))
if (count<3):
workflowExecution.goToOperation(1)
else:
workflowExecution.goToOperation(workflowExecution.getOperationsCount())2.2.58. Switch License
This operation releases the license used by the Nuix Engine when running a job in Rampiva Scheduler, and optionally acquires a different license depending on the license source option:
-
None - Does not acquire a Nuix license and runs the remaining operations in the workflow without access to the Nuix case.
-
NMS - Acquires a Nuix license from the NMS server specified.
-
CLS - Acquires a Nuix license from the Nuix Cloud License server.
-
Dongle - Acquires a Nuix license from a USB Dongle connected to the Engine Server.
-
Engine Default - Acquires a Nuix license from the default source from which the Engine acquired the original Nuix license when the job was started.
When specifying a Filter, the text provided will be compared against the available Nuix license name and description.
When specifying a Workers count of -1, the default number of workers that the Engine originally used will be selected.
| This operation is not supported for workflows executed in Rampiva Workflow. |
2.2.59. Close Case
This operation closes the current Nuix Case used in Rampiva Workflow. If the Nuix Workstation case is being used, it will be closed.
2.2.60. Close Nuix
This operation closes the Nuix Workstation window, releasing the licence acquired by this instance.
If the Close Rampiva Workflow option is selected, the Rampiva Workflow window showing the workflow progress and execution log is also closed.
| To release the memory acquired by the Nuix Workstation instance, the Rampiva Workflow window needs to be closed |
2.3. Parameters
When designing a workflow, parameters can be used in the workflow along with static text in every field which accepts user input such as search queries, file paths, production sets names, etc.
2.3.1. General Parameters
| These parameters do not depend on the previous workflow executions or user operations and can be used at any point in the workflow. |
Case
-
{case_name}
The name of the case. Example replacement:Globex vs. Initech -
{case_folder}
The folder in which the Nuix case resides. Example replacement:C:\Cases\Globex vs. Initech -
{previous_case_folder}
The folder in which the previously used Nuix case resides. Example replacement:C:\Cases\Globex vs. Initech -
{first_case_folder}
The folder in which the first Nuix used case resides. Example replacement:C:\Cases\Globex vs. Initech -
{case_prefix}
At most the first 5 alphabetic characters from the case name, to be used in document ID numbering schemes. Example replacement:GLOBE
Date and Time
-
{date}
The current date at execution, formatted usingYYYYMMDD. Example replacement for December 31, 2017:20171231 -
{time}
The current time at execution, formatted usingHHmmss. Example replacement for 4:30 PM:163000 -
{date_time}
The current date and time at execution, formatted usingYYYYMMDD-HHmmss. Example replacement:20171231-163000 -
{date_time_local}
The current date and time at execution, in local format as reported by Nuix. Example replacement:12/31/17 4:30 PM
Workflow
-
{workflow_name}
The name of the workflow. Example replacement:Standard Processing -
{workflow_state}
The execution state of the workflow. Example replacement:Running -
{workflow_log}
Text indicating the status of each workflow operation, up to the current point of execution. -
{workflow_status}
Tab-separated text table showing an overview of the workflow progress, up to the current point of execution. -
{workflow_status_html}
HTML table showing an overview of the workflow progress, up to the current point of execution. -
{rampiva_logo_html}
HTML image tag showing the Rampiva logo. -
{simple_style_html}
Simple HTML style code for the workflow progress table.
Environment
-
{server_name}
The name of the server running the workflow. Example replacement:srv1 -
{server_fqdn}
The fully qualified domain name (FQDN) of the server running the workflow. Example replacement:srv1.company.local
2.3.2. Dynamic Parameters
| These parameters only apply to operations performed during the execution of the workflow and will not retain values from previous executions or manual operations. |
Add Evidence
-
{data_timezone_id}
The source timezone of the data to use when adding evidence. See Joda Time Zones for a list of valid timezone IDs. -
{last_batch_load_guid}
The GUID of the last batch loaded into the case. Example:batch-load-guid:{last_batch_load_guid}will be replaced withbatch-load-guid:99fd2cc9ef564b498e28fb760d33ec83 -
{last_batch_load_date}
The date of the last batch loaded into the case. Example:{last_batch_load_date}will be replaced with20171231 -
{last_batch_load_date_time}
The date and time of the last batch loaded into the case. Example:{last_batch_load_date_time}will be replaced with20171231-163000 -
{last_batch_load_date_time_local}
The date and time of the last batch loaded into the case, in local format as reported by Nuix. Example:{last_batch_load_date_time_local}will be replaced with12/31/17 4:30 PM -
{last_evidence_guid}
The GUID of the last evidence loaded into the case. Example:path-guid:{last_evidence_guid}will be replaced withpath-guid:31d947842d994d33afb9cd0a0c7f6181 -
{last_evidence_name}
The name of the last evidence loaded into the case. The actual name assigned to the evidence might be different than the one specified in the workflow, for example, if an evidence with the same name previously existed in the case.
Example:path-name:"{last_evidence_name}"will be replaced withpath-name:"Evidence 1"
| Surround with quotes when using parameter within a query to ensure that whitespaces and handled correctly. |
Item Set
-
{last_item_set_name}
The name of the item set to which items were last added. Example:item-set:"{last_item_set_name}"will be replaced withitem-set:"Documents of interest"
item-set-originals:"{last_item_set_name}"
| Surround with quotes when using parameter within a query to ensure that whitespaces and handled correctly. |
-
{last_item_set_originals_batch}
The originals batch ID of the last item set to which items were added.
Example:item-set-batch:"{last_item_set_originals_batch}"will be replaced withitem-set-batch:"ee4c28bd194e4680949bab95bab8d192;originals;Emails and PDF"
| Surround with quotes when using parameter within a query to ensure that whitespaces and handled correctly. |
When performing a deduplication by family based on Message-ID or MAPI Search Key in Nuix 7.4 or earlier, two batches will be created: one for top-level items (with suffix TL) and another one for non-top-level items (with suffix NonTL). To query for original items in both of these batches, use syntax:item-set-batch:("{last_item_set_originals_batch} TL" OR "{last_item_set_originals_batch} NonTL")
|
-
{last_item_set_duplicates_batch}
The duplicates batch ID of the last item set to which items were added.
Example:item-set-batch:"{last_item_set_duplicates_batch}"will be replaced withitem-set-batch:"ee4c28bd194e4680949bab95bab8d192;duplicates;Emails and PDF" -
{last_item_set_batch}
The batch ID of the last item set to which items were added, including both original and duplicate items.
Example:item-set-batch:"{last_item_set_batch}"will be replaced withitem-set-batch:"ee4c28bd194e4680949bab95bab8d192;Emails and PDF"
Production Set
-
{last_production_set_name}
The name of the last production set created in this workflow session. The actual name assigned to the production set might be different than the one specified in the workflow, for example, if frozen production set with the same name previously existed in the case. Example:production-set:"{last_production_set_name}"will be replaced withproduction-set:"Documents of interest"
| Surround with quotes when using parameter within a query to ensure that whitespaces and handled correctly. |
-
{export_production_set_name}
The name of the production set being exported. Example:{case_path}\Export{export_production_set_name}will be replaced withC:\Cases\Globex vs. Initech\Export\Documents of interest -
{docid_start_numbering_at}
Set this parameter to specify a custom document ID start number. Example: 100000
| Select the option Start numbering at in the configuration of the Add Items to Production Set operation for this parameter to have an effect. |
-
{docid_digits}
Set this parameter to specify a custom number of digits. Example: 7 -
{docid_family_digits}
Set this parameter to specify a custom number of family digits. Example: 3
| Select the numbering scheme Family Document ID in the configuration of the Add Items to Production Set operation for this parameter to have an effect. |
The {docid_…} parameters only have an effect if a new production set is created.
|
Legal export
-
{last_export_folder}
The folder of the last legal export. Example:last_export_folderwill be replaced withC:\Cases\Globex vs. Initech\Export\Production 20170101
| Surround with quotes when using parameter within a query to ensure that whitespaces and handled correctly. |
-
{export_production_set_name}
The name of the production set being exported. Example:{case_path}\Export{export_production_set_name}will be replaced withC:\Cases\Globex vs. Initech\Export\Documents of interest -
{relativity_native_copy_mode}
Set this parameter to specify a the Relativity native copy mode. Example: SetFileLinks
Metadata
-
{last_metadata_export_file}
The full file name and path of the last metadata export, from operations Generate Domain Fields, Generate Duplicate Custodians, Generate Duplicate Duplicate Fields and Metadata Export. Example:C:\Cases\Globex vs. Initech\Export\Metadata.csv -
{metadata_profile}
Set this parameter to specify a custom metadata profile for operations Legal Export, Metadata Export and Relativity Metadata Overlay . Example: Context
Report
-
{last_report_file}
The full file name and path of the last report produced. Example:C:\Cases\Globex vs. Initech\Reports\20170101 Processing Report.xlsx
Script
-
{last_script_output}
The text outputted by the script, for example using the print method. If no text was outputted by the script, this will be blank. -
{last_script_error}
The description of error encountered during script execution. If no execution was encountered, this will be blank. -
{last_script_return_value}
The string representation of the object returned by the script. If no object was returned, this will benull.
Use case
-
{case_timezone_id}
The timezone to use when opening cases. See Joda Time Zones for a list of valid timezone IDs.
2.3.3. Scheduler Parameters
| These parameters only apply to workflows ran through Rampiva Scheduler. |
-
{job_name}
The name of the job -
{job_notes}
The notes assigned to the job -
{job_id}
The system ID of the job -
{job_resource_pool_name}
The name of the Resource Pool to which the job was assigned -
{job_resource_pool_id}
The system ID of the Resource Pool to which the job was assigned -
{job_priority}
The job priority -
{job_submitted_by}
The name of the user who submitted the job -
{job_submitted_date}
The time and date when the job was submitted -
{job_engine_name}
The name of the engine that is running the job -
{job_engine_id}
The system ID of the engine that is running the job -
{job_server_name}
The name of the server hosting the engine that is running the job -
{job_server_id}
The system ID of the server hosting the engine that is running the job -
{matter_name}
The name of the matter under which the job was submitted, if available. -
{matter_id}
The system ID of the matter under which the job was submitted, if available. -
{client_name}
The name of the client under which the job was submitted, if available. -
{client_id}
The system ID of the client under which the job was submitted, if available.
2.3.4. Profile Parameters
| These parameters are only visible in the profile of the user that defined them. |
Parameters can be defined by the user from the Workflow Designer Options menu.
In each user session, define a parameter {user_email} which holds the email address of the analyst. Then use this parameter in the email Notification operation
to ensure that the user who started the workflow, receives the notification email.
|
2.3.5. Configuration Parameters
| These parameters are defined using the Configuration operation and are only valid during the workflow execution. |
2.3.6. Protected Parameters
Parameters with the name ending in _protected or _password are treated as Protected Parameters. The values of these parameters can be set
using the Configuration operation, but can only be read by the following operations:
-
Use Relativity Workspace, in the Relativity password field. -
Notify, in the SMTP password field.
| The values of Protected Parameters should only be entered during the workflow execution. If entered in the workflow design, the values of Protected Parameters will be saved in cleartext in the workflow file. |
2.3.7. Masked Parameters
Parameters with the name ending in _masked will have their values masked in the user interface, but can be retrieved by any operation.
| The values of Masked Parameters are only masked from the user interface, but are saved in cleartext in the workflow file. |
| When running workflows in Rampiva Scheduler, all workflows execute under the user account configured to run the Rampiva Scheduler service. |
3. Workflow Execution
Workflow Execution can be initiated either from Nuix using the Scripts → Rampiva → Workflow Execution menu or from the Workflow Design, using the File → Workflow Execution menu.
When choosing to Run a workflow, you are prompted to select the case in which to run the workflow.
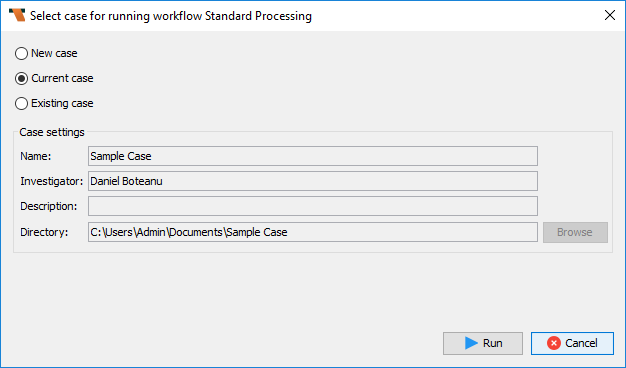
The following options are available:
-
New case: Creates a new case and runs the workflow in this case.
-
Current case: Runs the workflow in the case currently open in Nuix Workstation (or the case that was open when Rampiva Workflow was started).
-
Existing case: Runs the workflow in an existing case specified by the Directory field.
After starting the execution of a workflow, a log of the execution is presented in the Execution Log pane.
The workflow execution can be interrupted with the Pause and Stop buttons. Although some support pausing and stopping mid-execution, it should be expected that the workflow will pause or stop after the current operation completed.
The workflow execution can be aborted with the Abort Execution menu item using File → Abort Execution.
| This will terminate any operation running and might corrupt the Nuix case. |
3.1. Email Notifications
Rampiva Workflow can send automatic email notifications when a workflow is executing, even if no Notify Operations are explicitly added to the workflow. This feature can be configured from the Options menu.
The following notification frequencies are available:
-
Disabled: No automatic workflow execution email notifications will be sent.
-
On workflow start/complete: A notification will be sent for workflow start, pause, stop, finish, and error events.
-
On operation complete: A notification will be sent for workflow events and when each operation completes.
| To avoid sending multiple emails within a short time period, use the Buffer emails for option. This will have the effect of waiting the predefined time before sending a notification email, unless the workflow execution finished in which case the email will be sent right away. |
4. Change Log
See Changelog.html